资源管理
yarn
- 是什么
一个作业调度和集群资源管理的框架。YARN的基本思想是将资源管理和作业调度/监视的功能拆分为单独的守护程序。
ResourceManager是在系统中所有应用程序之间仲裁资源的最终权限。
NodeManager是每台机器的框架代理,负责容器,监视其资源使用情况(cpu,内存,磁盘,网络),并将其报告给ResourceManager / Scheduler。

自己理解的YARN
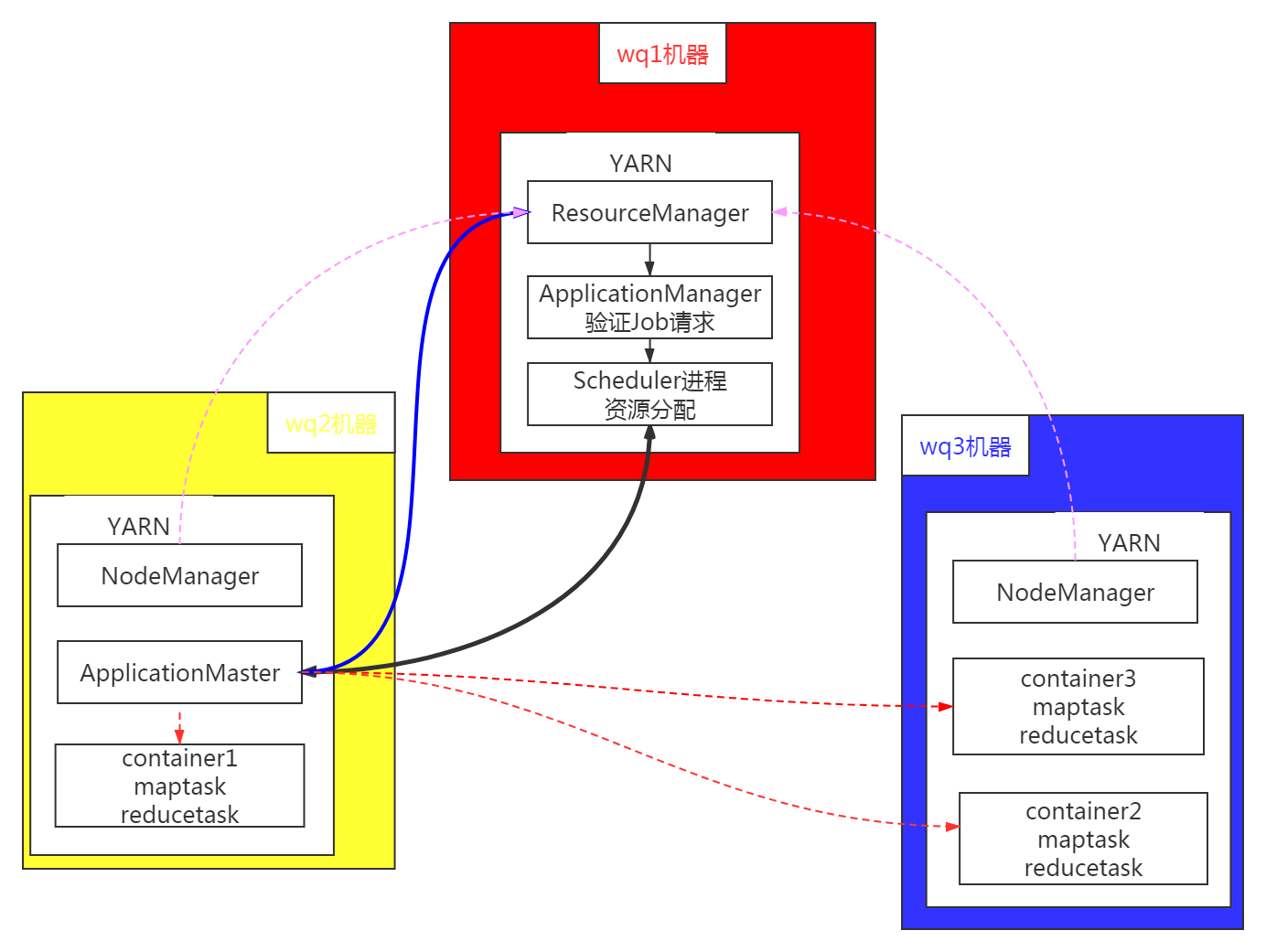
第一步:客户端提交任务(MapReduce, Java应用,Apache Spark任务等)到ResourceManager,同时传递一个命令,用于在NodeManager节点中启动任意一个container来运行ApplicationMaster;
第二步:Master节点上的ApplicationManager验证Job请求,然后传递给Scheduler进程进行资源分配;
第三步:Scheduler进程从某个Slave节点分配一个container来运行ApplicationMaster;
第四步: NodeManager后台进程在其中一个container中启动ApplicationMaster,使用第一步传递过来的命令。ApplicationMaster于是成为了任何应用的第一个container;
第五步: ApplicationMaster将数据的位置(如保存着哪个Slave节点上)、所需CPU、内存量等信息提供给ResourceManager,与其协商如何分配其他container;
第六步: ReourceManager在Slave节点中进行最合理的资源分配,然后将节点详细信息等返回给ApplicationMaster;
第七步: 然后,ApplicationMaster将请求(如建议在哪个Slave上启动container)发给NodeManagers;
第八步: ApplicationMaster管理所请求container运行时的资源使用情况,并在任务完成后通知ResourceManager;
第九步: NodeManagers周期性地将自身的状态(如可使用资源情况)通知ResourceManager,作为Scheduler在集群中协调新应用的依据;
第十步: 任意一个Slave节点失败时,ResourceManager会试图在一个最合适的Slave节点上分配一个新的container,这样ApplicationMaster可使用新的container继续工作下去;
– 配置
`yarn-site.xml`
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>wq1:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>wq1:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>wq1:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>wq1:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>wq1:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
zookeeper3.4.10
- 是什么
分布式应用程序的高性能协调服务。Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题。ZooKeeper提供的服务包括:分布式消息同步和协调机制、服务器节点动态上下线、统一配置管理、负载均衡、集群管理等。
zookeeper选举机制

myid是自己设置的,每个节点启动时,拿到自己的zxid(事务ID),从历史数据中获取,默认值为0;实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数
- 启动过程的选举
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的Leader,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它成为Follower。
(5)服务器5启动,同4一样成为Follower。
注意,如果按照5,4,3,2,1的顺序启动,那么5将成为Leader,因为在满足半数条件后,ZooKeeper集群启动,5的Id最大,被选举为Leader。
优先比较事物id,事物id相同的话,比较机器的id
- 运行过程中的选举
在ZooKeeper中,服务器和客户端之间维持的是一个长连接,在 SESSION_TIMEOUT 时间内,服务器会确定客户端是否正常连接(客户端会定时向服务器发送heart_beat),服务器重置下次SESSION_TIMEOUT时间。因此,在正常情况下,Session一直有效,并且zk集群所有机器上都保存这个Session信息。在出现问题的情况下,客户端与服务器之间连接断了(客户端所连接的那台zk机器挂了,或是其它原因的网络闪断),这个时候客户端会主动在地址列表(初始化的时候传入构造方法的那个参数connectString)中选择新的地址进行连接。